

Let's Dive into Seq2Seq Learning


Table of contents

No headings in the article.
In the era of ever-growing landscape of Machine Learning Field, one paradigm stands out for its remarkable ability to adapt and applications that is Sequence-to-Sequence (Seq2Seq) Learning. It is all about training models to convert sequences from one domain to sequences in another domain (e.g. Converting Text of English to Hindi like google translator). From language translation, speech recognition to Word Detection, this powerful approach that is defined to observe how machines understand and generate sequential data.
At its lowest levels, Sequence to Sequence learning revolves around the idea of converting input sequences into output sequences. This architecture, is based on recurrent neural networks (RNNs) or more advanced models like transformers, enables machines to learn and generate sequences of various lengths. Whether it's translating a sentence from English to Hindi or summarizing a document, Seq2Seq also models excel at handling sequential data.
There is basically two main phases of Seq2Seq Learning:
Encoding Phase:
Input Sequence Processing: In this step the input sequences is fed into the encoder one at a time. At each time step, the encoder processes the input and updates its internal state. In RNN based Seq2Seq models, the internal state is a hidden state vector that retains information about the entire input sequence.
Contextual Representation: Here the hidden state of the encoder work as a contextual representation of the entire input sequence. This representation take out the relevant information needed for generating the output sequence.
Decoding Phase:
Initial State: Here In the first step of decoder the decoder is initialized with the contextual representation that is generated from the encoder. At the beginning of decoding, the hidden state of the decoder captures the necessary information about the input sequence.
Output Generation: Then decoder generates the output sequences one at a time. At each time step, it considers the current context that captured by the hidden state and the previously generated elements of the output sequence.
Sequential Output: The decoder continues generating elements until a specified termination condition is met, such as reaching a maximum length or producing an end-of-sequence token.
Attention mechanisms further enhance Seq2Seq models by allowing them to focus on specific parts of the input sequence during decoding, improving both accuracy and efficiency.
Here I got one good picture to understand the concept. It is translating english to french.
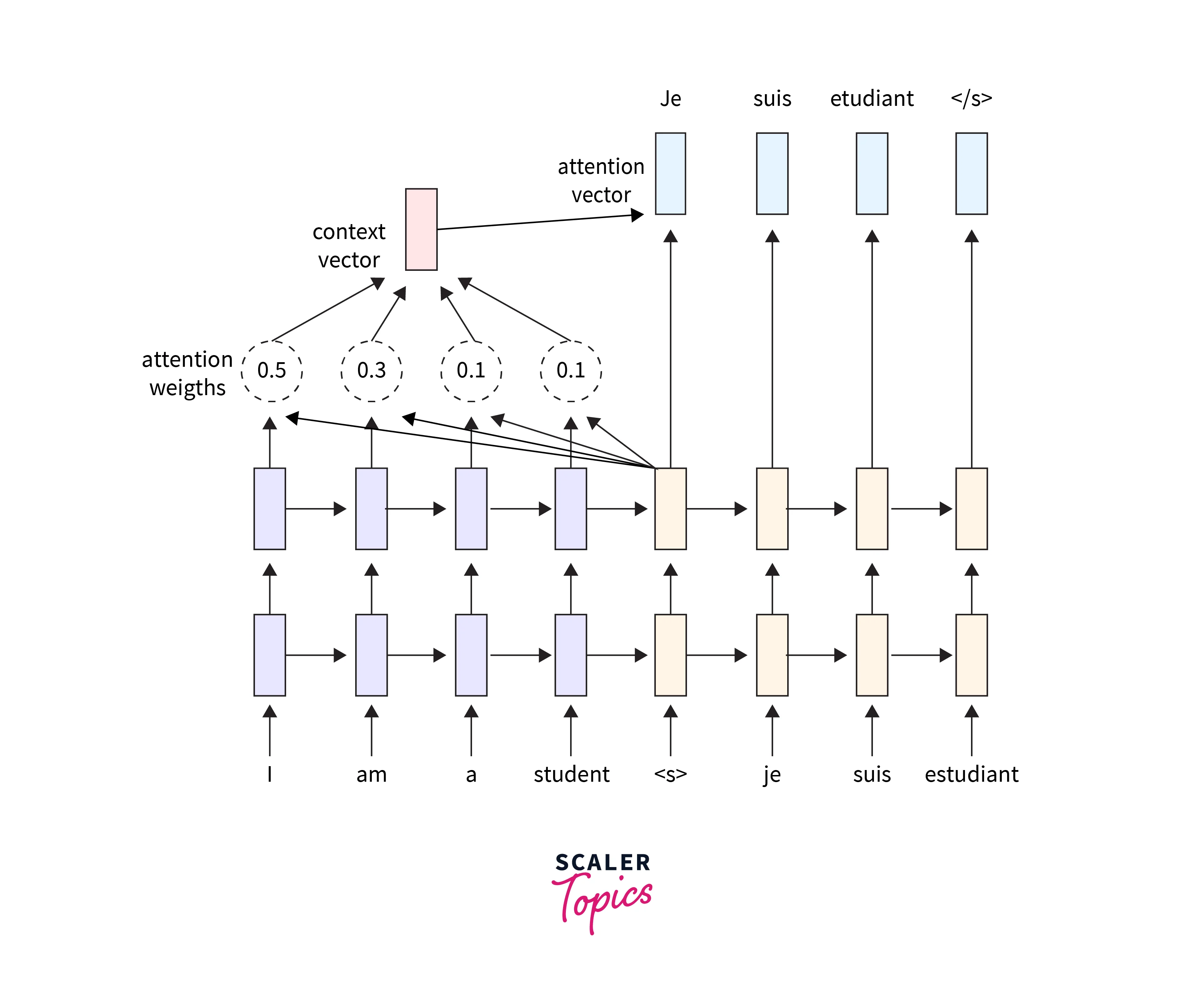
Seq2Seq Learning is also making remarkable progress in field of Natural Language Processing (NLP). Language translation models, like Google's Neural Machine Translation (GNMT), leverage Seq2Seq architectures to provide more contextually accurate and fluent translations. Beyond language translation, Seq2Seq learning plays a crucial role in speech recognition technology. Models like Listen, Attend, and Spell (LAS) utilize Seq2Seq architectures to transcribe spoken words into text accurately. I have personally used Sequence to Sequence Learning in Captcha Detection Project that I am working on currently Captcha Detection.
Sequence-to-Sequence (Seq2Seq) learning emerging as a transformative force with reshaping the landscape of AI. From breaking language barriers to enhancing speech recognition, its encoder-decoder architecture and attention mechanisms showcase the beauty of handling sequential data. As we navigate the challenges and embrace innovations.