

Exploring Kernal Insights with Support Vector Machine (SVM).


Support Vector Machines that are SVM used in the realm of machine learning, that can be used as both in classification and regression tasks. SVM inception traces back to the 1960s, but it wasn't until the 1990s that SVM went into refinement, so that it can be used in supervised learning. This article delves into the realm of SVMs, educating their functioning and practical applications in the real world. So let's the article with the question and that is.
What is a Support Vector Machine?
A Support Vector Machine is basically the classifier at its essence, designed to design an optimal hyperplane that segregates Or divide the data points into distinct classes. The method lies in selecting this hyperplane to maximize the gap between the hyperplane and the closest data points from each class. the reason nomenclature is Support Vector.
The goal of the SVM algorithm is to create the best line or decision boundary that can segregate n-dimensional space into classes so that we can easily put the new data point in the correct category in the future. This best decision boundary is called a hyperplane.
SVM chooses the extreme points/vectors that help in creating the hyperplane. These extreme cases are called support vectors, and hence the algorithm is termed as Support Vector Machine. Consider the below diagram in which there are two different categories that are classified using a decision boundary or hyperplane:
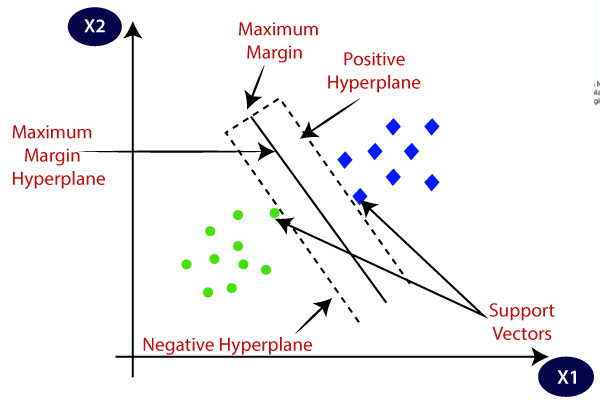
Hyperplane: There can be multiple lines/decision boundaries to segregate the classes in n-dimensional space, but we need to find out the best decision boundary that helps to classify the data points. This best boundary is known as the hyperplane of SVM.
Support Vector: The data points or vectors that are the closest to the hyperplane and which affect the position of the hyperplane are termed as Support Vector. Since these vectors support the hyperplane, hence called a Support vector.
Now, let's see how it works first, let's see the theory then I’ll also be showing you how it works practically.
We basically have to consider 4 main functions for performing SVM.
1. Linear Separability: Support Vector Machine operates under the assumption of linear separability, that basically implies that the data can be partitioned into number of classed classes via a straight line or hyperplane in higher dimensions.
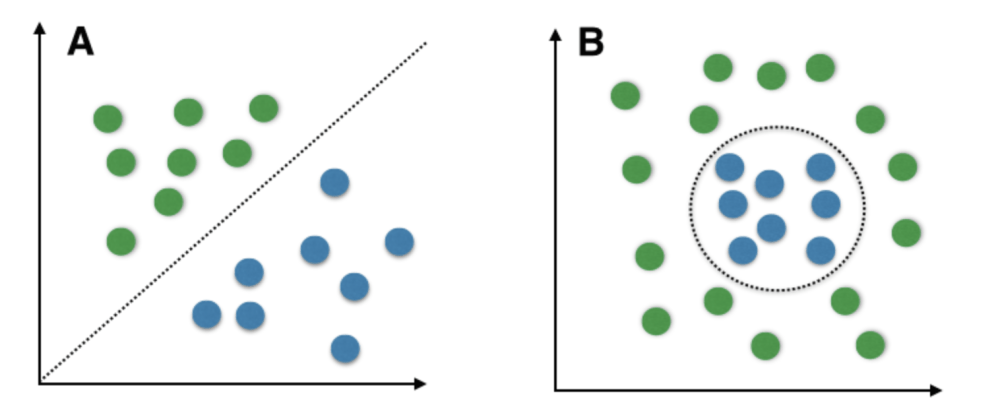
2. Margin Maximization: Support Vector Machine primary objective is to revolves around maximizing the margin that is gap between the planes , thereby ensuring superior generalization and robustness of the classifier while classifying the data.
3. Kernel Trick: In the situations where data isn't linearly separable, SVM uses something called as the kernel trick to map input data into a higher dimensional space conducive to linear separation. It has various kernel functions such as linear, polynomial, radial basis function (RBF), and sigmoid facilitate this process in training.
4. Optimization: Support Vector Machine tackles an optimization problem to pinpoint the optimal hyperplane by minimizing a cost function that is used for training, which basically uses for encompassing the margin and a regularization term to overfitting.
Python Implementation of SUPPORT VECTOR MACHINE
Here, I have taken the Parkinson’s Disease Dataset for training with SVM
Importing all Necessary Libraries

Second Step involves reading the Dataset.
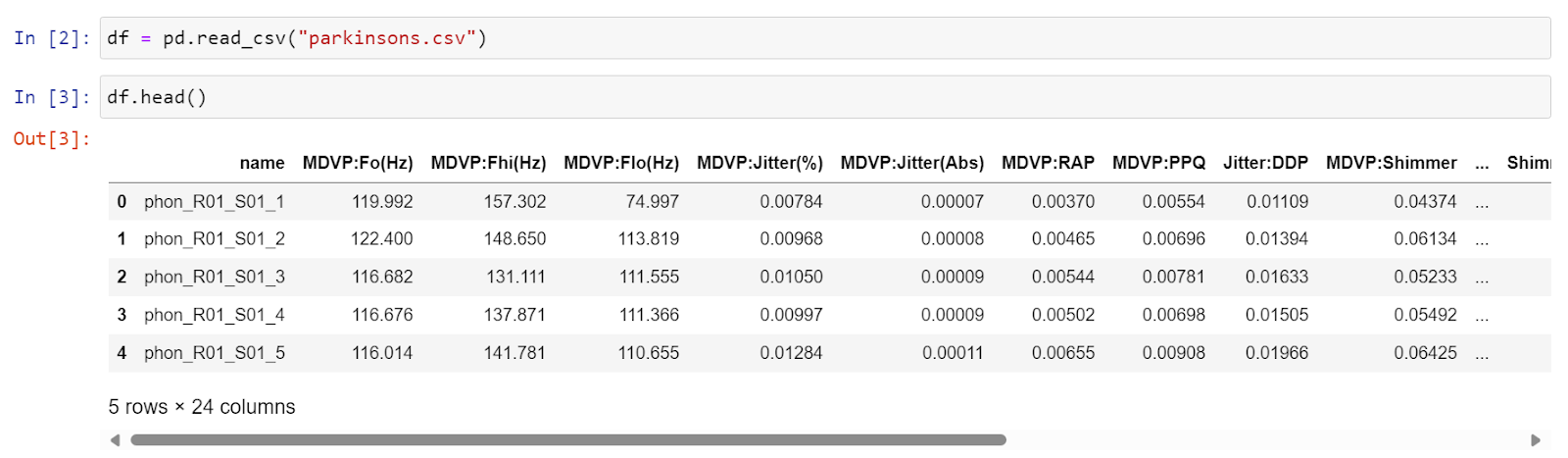
Exploring the Parkinson’s disease dataset.
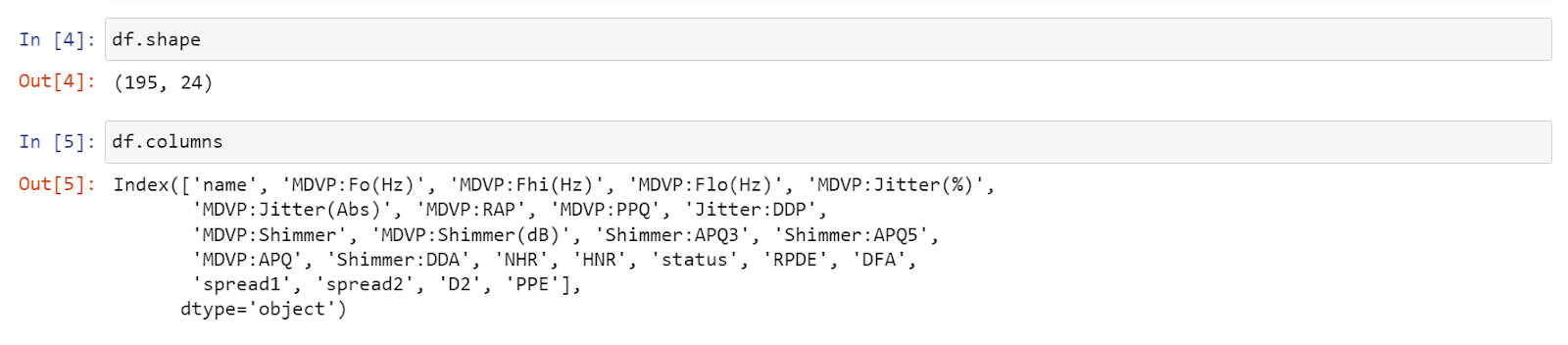
I have preprocessed it earlier so it does not contain any null values.
Now let’s the relationships between the features of the dataset.
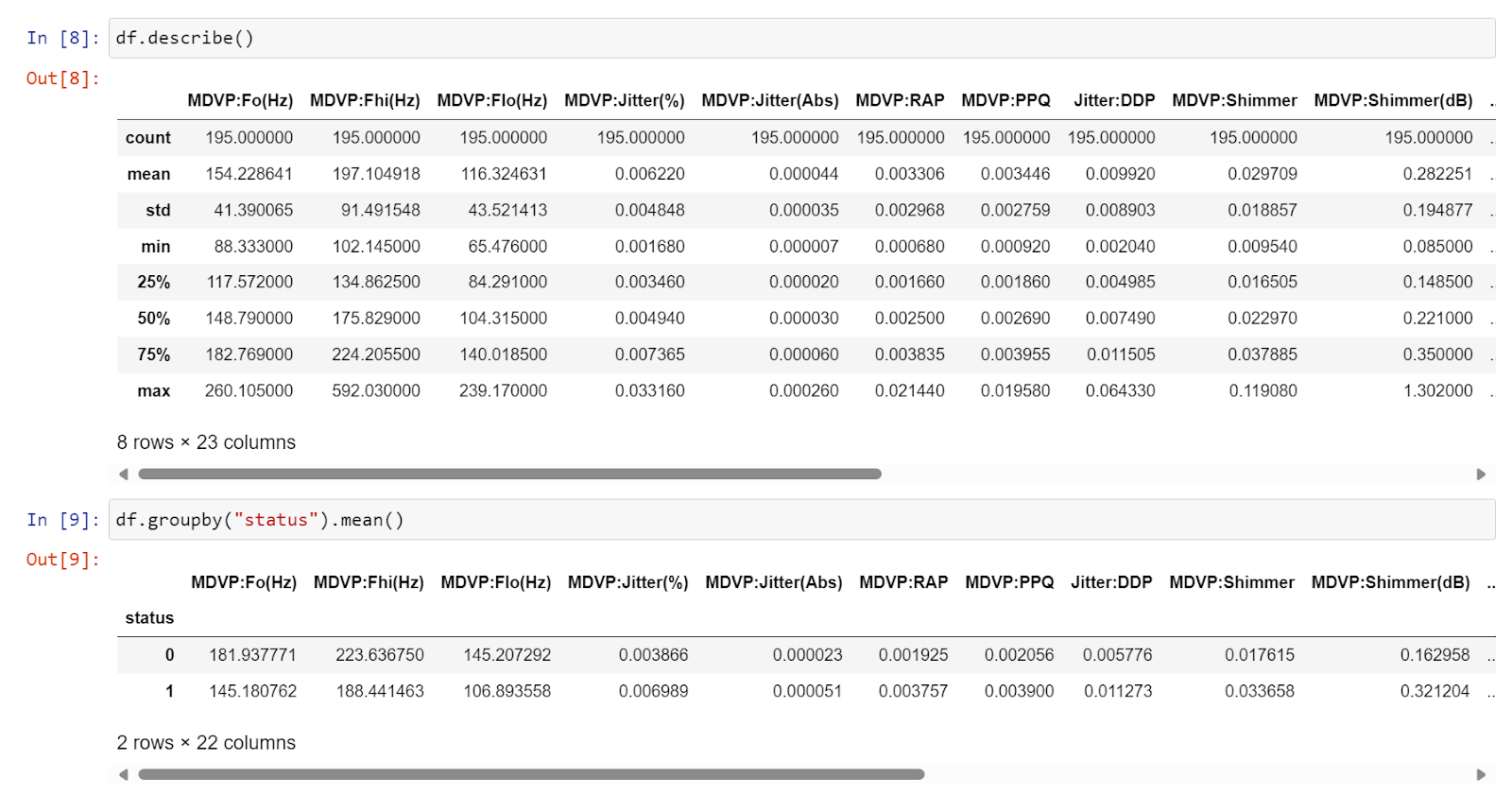
Lets define our target and features variable.

Using MinMaxScaler to scale the dataset between -1,1

Selecting SVM for our model

Support Vector Machine has various advantages to be used as Supervised Machine Learning.
1. Effective in Higher Dimensions: SVM thrives in higher dimensional spaces, making it ideal for many tasks with numerous features like text classification and image recognition.
2. Less Overfitting: By prioritizing gap maximization between the classes, SVM exhibits resilience to overfitting with other classifiers, which enhances the model generalization powers.
3. Versatility: Support Vector Machine adapts and handles both linear and non-linear classification tasks with help of its kernel functions, allowing for modeling intricate and more efficient data relationships.
4. Memory Efficiency: It also enhances the memory efficiency by leveraging only a subset of training that is the support vector to give the decision boundary that renders SVM memory efficiency, mainly for voluminous datasets.
5. It also has various applications like Text Classification, Image Recognition, Bioinformatics, etc.
Conclusion:
Support Vector Machines emerging as potential machine learning tools, which can work in both linear and non-linear classification areas. By prioritizing margin maximization and by handling diverse datasets, SVMs have impressive robustness, generalization, and versatility. Spanning domains like text classification, image recognition, bioinformatics, and finance, SVMs continue to work for significance by exponential advancements across various domains in the realm of machine learning.